![]()
![]()

![]()
rsparse is an R package for statistical learning
primarily on sparse matrices - matrix
factorizations, factorization machines, out-of-core regression.
Many of the implemented algorithms are particularly useful for
recommender systems and NLP.
We’ve paid some attention to the implementation details - we try to avoid data copies, utilize multiple threads via OpenMP and use SIMD where appropriate. Package allows to work on datasets with millions of rows and millions of columns.
Matrix::RsparseMatrix. However common R
Matrix::CsparseMatrix (dgCMatrix) will be
converted automatically.WRMF class and
constructor option feedback = "explicit". Original paper
which indroduced MMMF could be found here.
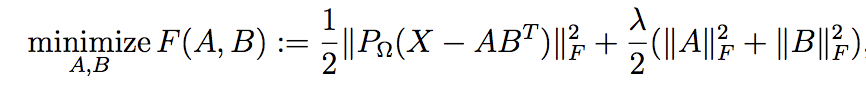
WRMF class and
constructor option feedback = "implicit". We provide 2
solvers:
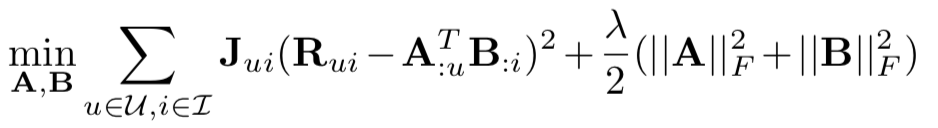
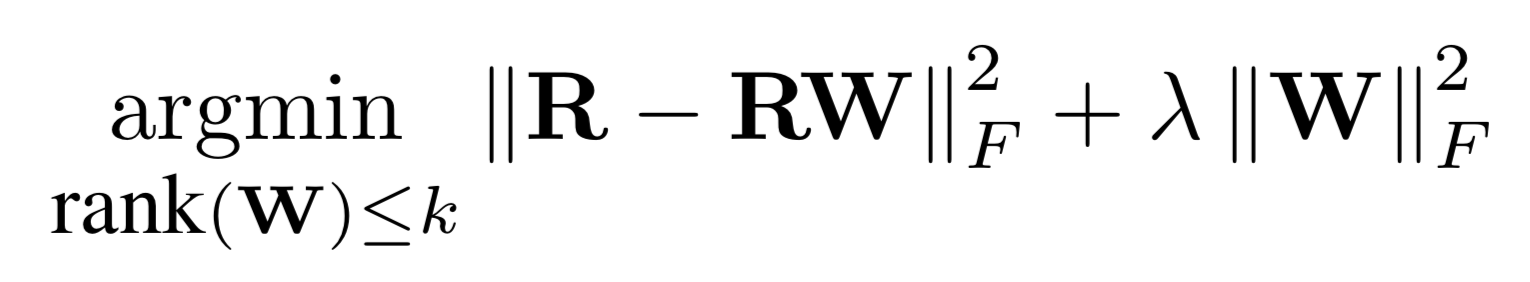
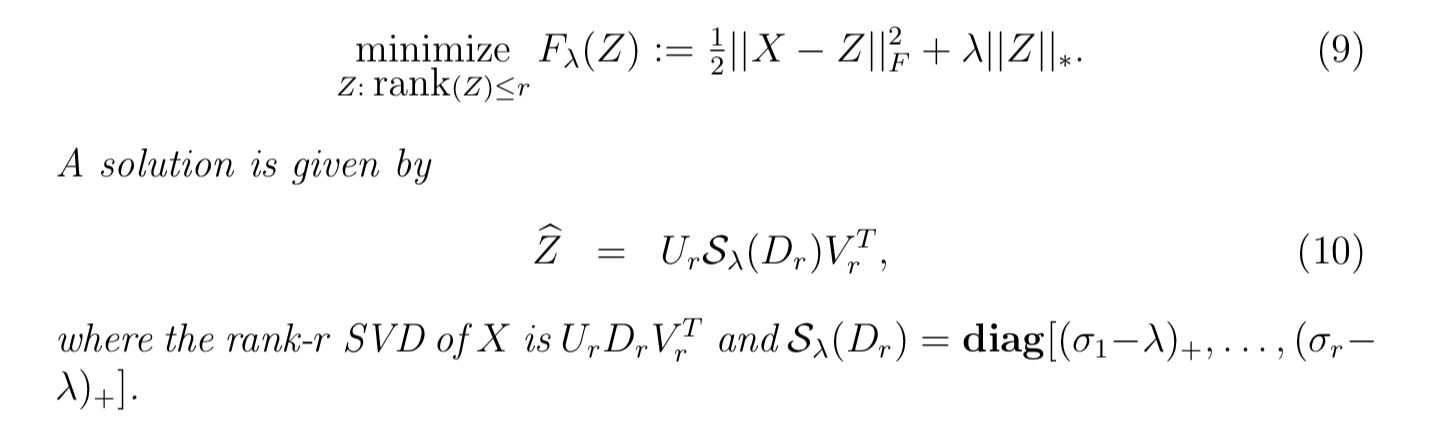
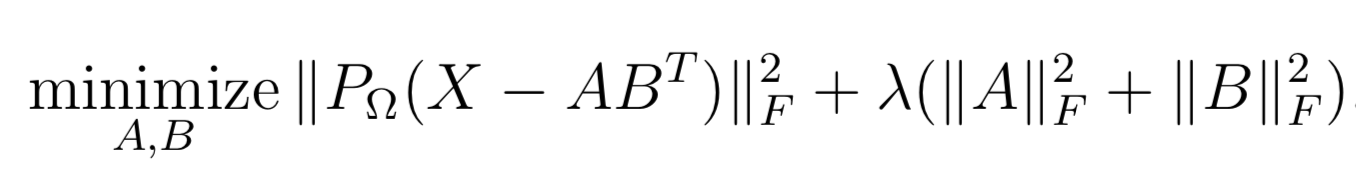
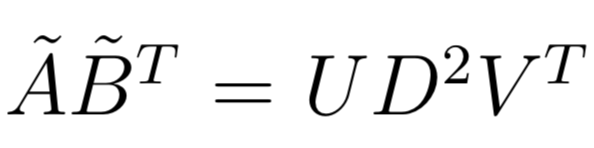
Note: the optimized matrix operations which rparse
used to offer have been moved to a separate
package
Most of the algorithms benefit from OpenMP and many of them could utilize high-performance implementations of BLAS. If you want to make the maximum out of this package, please read the section below carefully.
It is recommended to:
~/.R/Makevars. For example on recent processors (with AVX
support) and compiler with OpenMP support, the following lines could be
a good option:CXX11FLAGS += -O3 -march=native -fopenmp
CXXFLAGS += -O3 -march=native -fopenmpIf you are on Mac follow the instructions at https://mac.r-project.org/openmp/.
After clang configuration, additionally put a
PKG_CXXFLAGS += -DARMA_USE_OPENMP line in your
~/.R/Makevars. After that, install rsparse in
the usual way.
Also we recommend to use vecLib - Apple’s implementations of BLAS.
ln -sf /System/Library/Frameworks/Accelerate.framework/Frameworks/vecLib.framework/Versions/Current/libBLAS.dylib /Library/Frameworks/R.framework/Resources/lib/libRblas.dylibOn Linux, it’s enough to just create this file if it doesn’t exist
(~/.R/Makevars).
If using OpenBLAS, it is highly recommended to use the
openmp variant rather than the pthreads
variant. On Linux, it is usually available as a separate package in
typical distribution package managers (e.g. for Debian, it can be
obtained by installing libopenblas-openmp-dev, which is not
the default version), and if there are multiple BLASes installed, can be
set as the default through the Debian
alternatives system - which can also be used for MKL.
By default, R for Windows comes with unoptimized BLAS and LAPACK
libraries, and rsparse will prefer using Armadillo’s
replacements instead. In order to use BLAS, install
rsparse from source (not from CRAN), removing the
option -DARMA_DONT_USE_BLAS from
src/Makevars.win and ideally adding
-march=native (under PKG_CXXFLAGS). See this
tutorial for instructions on getting R for Windows to use OpenBLAS.
Alternatively, Microsoft’s MRAN distribution for Windows comes with
MKL.
Note that syntax is these posts/slides is not up to date since package was under active development
Here is example of rsparse::WRMF on lastfm360k dataset in
comparison with other good implementations:

We follow mlapi conventions.
Don’t forget to add DARMA_NO_DEBUG to
PKG_CXXFLAGS to skip bound checks (this has significant
impact on NNLS solver)
PKG_CXXFLAGS = ... -DARMA_NO_DEBUGGenerate configure:
autoconf configure.ac > configure && chmod +x configure